
 FCVID: Fudan-Columbia Video Dataset
FCVID: Fudan-Columbia Video Dataset
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
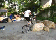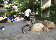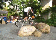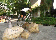 |
 |
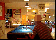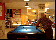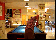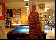 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Recognizing visual contents in unconstrained videos has become a very important problem for many applications, such as Web video search and recommendation, smart advertising, robotics, etc. Existing datasets for video content recognition are either small or do not have reliable manual labels. In this project, we construct and release a new dataset called Fudan-Columbia Video Dataset (FCVID), containing 91,223 Web videos annotated manually according to 239 categories. We believe that the release of FCVID can stimulate innovative research on this challenging and important problem.
The categories in FCVID cover a wide range of topics like social events (e.g., “tailgate party”), procedural events (e.g., “making cake”), objects (e.g., “panda”), scenes (e.g., “beach”), etc. These categories were defined very carefully and organized in a hierarchy of 11 high-level groups. Specifically, we conducted user surveys and used the organization structures on YouTube and Vimeo as references, and browsed numerous videos to identify categories that satisfy the following three criteria: (1) utility – high relevance in supporting practical application needs; (2) coverage – a good coverage of the contents that people record; and (3) feasibility – likely to be automatically recognized in the next several years, and a high frequency of occurrence that is sufficient for training a recognition algorithm. In order to minimize subjectivity, multiple people were involved in both the category definition and the manual annotation processes.
Click here to see a full hierarchy of FCVID categories with visual examples.
The dataset, including videos, labels, a standard train/test split, several pre-computed descriptors, surrounding texts and a category hierarchy, can be obtained by sending a request email to us. Specifically, the researchers interested in FCVID should download and fill up this Agreement Form and send it back to Zuxuan Wu (zxwu AT fudan.edu.cn; Email title: FCVID data request). We will then send you the download instructions at our discretion.
The provided descriptors include SIFT, features based on the Convolutional Neural Networks, the Improved Dense Trajectories (IDT) and two audio features. The SIFT, IDT and audio features are quantized using the bag-of-words representation.
Please cite this paper if the dataset helps your research.
@article{FCVID,
author = {Yu-Gang Jiang and Zuxuan Wu and Jun Wang and Xiangyang Xue and Shih-Fu Chang},
title = {Exploiting Feature and Class Relationships in Video Categorization with Regularized Deep Neural Networks},
journal = {{IEEE} Transactions on Pattern Analysis and Machine Intelligence},
volume = {40},
number = {2},
pages = {352--364},
year = {2018},
url = {https://doi.org/10.1109/TPAMI.2017.2670560},
doi = {10.1109/TPAMI.2017.2670560},
}
Number of Videos: 91,223
Number of Categories: 239
Total Duration: 4,232.2 hours
Average Video Duration: 167 seconds